import numpy as np
from scipy.optimize import linprog
def basis_pursuit(X, y):
n, p = X.shape
A = np.column_stack([X, -X])
assert A.shape == (n, 2*p)
result = linprog(c=np.ones(2*p), A_eq=A, b_eq=y)
positive_part = result.x[:p]
negative_part = result.x[p:]
return positive_part - negative_partDonoho-Tanner phase transition for sparse recovery
def compute(n, p, s, seed=None):
rng = np.random.default_rng(seed=seed)
X = rng.standard_normal(size=(n, p))
beta_star = np.hstack([np.ones(s), np.zeros(p- s)])
assert beta_star.shape == (p, )
y = X@beta_star
return {'n': n, 'p': p, 's': s, 'seed': seed,
'perfect recovery': np.allclose(basis_pursuit(X, y), beta_star)}
compute(50, 100, 20, seed=6){'n': 50, 'p': 100, 's': 20, 'seed': 6, 'perfect recovery': True}p = 100
params = [dict(n=n, p=p, s=s, seed=seed)
for s in range(1, p+1)
for n in range(1, p+1)
for seed in range(50)
]from joblib import Parallel, delayed
f"Will now launch {len(params)} parallel tasks"'Will now launch 500000 parallel tasks'# Heavy computation
data = Parallel(n_jobs=18, verbose=2)(delayed(compute)(**d) for d in params)[Parallel(n_jobs=18)]: Using backend LokyBackend with 18 concurrent workers.
[Parallel(n_jobs=18)]: Done 5 tasks | elapsed: 0.2s
[Parallel(n_jobs=18)]: Done 428 tasks | elapsed: 0.4s
[Parallel(n_jobs=18)]: Done 9500 tasks | elapsed: 2.8s
[Parallel(n_jobs=18)]: Done 27612 tasks | elapsed: 7.4s
[Parallel(n_jobs=18)]: Done 50972 tasks | elapsed: 13.8s
[Parallel(n_jobs=18)]: Done 79452 tasks | elapsed: 22.3s
[Parallel(n_jobs=18)]: Done 113180 tasks | elapsed: 35.4s
[Parallel(n_jobs=18)]: Done 152028 tasks | elapsed: 52.0s
[Parallel(n_jobs=18)]: Done 196124 tasks | elapsed: 1.2min
[Parallel(n_jobs=18)]: Done 245340 tasks | elapsed: 1.6min
[Parallel(n_jobs=18)]: Done 299804 tasks | elapsed: 2.1min
[Parallel(n_jobs=18)]: Done 359388 tasks | elapsed: 2.6min
[Parallel(n_jobs=18)]: Done 424220 tasks | elapsed: 3.1min
[Parallel(n_jobs=18)]: Done 494172 tasks | elapsed: 3.7min
[Parallel(n_jobs=18)]: Done 500000 out of 500000 | elapsed: 3.8min finished#%config InlineBackend.figure_formats = ['svg']
import seaborn as sns
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib as mpl
mpl.rcParams['figure.dpi'] = 150
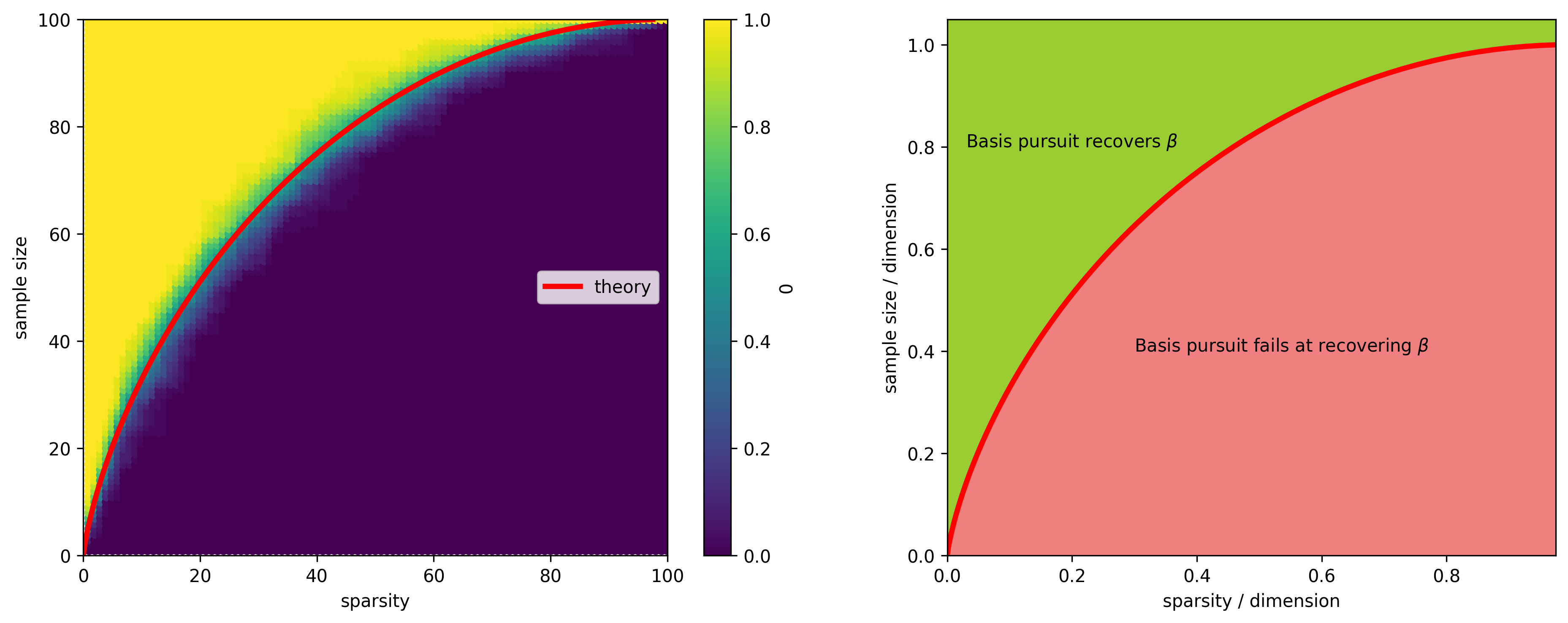
piv = pd.pivot_table(pd.DataFrame(data),
values='perfect recovery',
index='n',
columns='s')
ax = sns.heatmap(piv)
plt.ylabel('sample size')
plt.xlabel('sparsity')
ax.invert_yaxis()
from scipy.stats import norm
f = norm.pdf
Phi = norm.cdf
F = lambda t: 2*( (1+t**2)*Phi(-t) - t*f(t) )
delta = lambda t: 4*f(t)/(2*( t*(1-2*Phi(-t)) + 2*f(t) ))
s_max = lambda t: (delta(t) - F(t))/( (1+t**2) - F(t))Code
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import matplotlib as mpl
mpl.rcParams['figure.dpi'] = 150
fig, (ax1, ax2) = plt.subplots(1, 2, gridspec_kw={'width_ratios': [1.2, 1]})
fig.set_size_inches(15, 5.5)
piv = pd.pivot_table(pd.DataFrame(data),
values='perfect recovery',
index='n',
columns='s')
piv.unstack().reset_index().plot(x='s', y='n', c=0, kind='scatter', ax=ax1)
grid = np.linspace(0.02, 10, num=500)
ax1.plot(100 * s_max(grid), 100 * delta(grid), color='red', label='theory', linewidth=3)
ax1.set_xlabel('sparsity')
ax1.set_ylabel(r'sample size')
ax1.legend()
ax2.plot(s_max(grid), delta(grid), color='red', label='theory', linewidth=3)
ax2.fill_between(s_max(grid), delta(grid), color="lightcoral")
maxy = ax2.get_ylim()[1]
ax2.fill_between(s_max(grid), delta(grid), maxy, color="yellowgreen")
ax2.text(0.03, 0.8 ,"Basis pursuit recovers $\\beta$")
ax2.text(0.3, 0.4 ,"Basis pursuit fails at recovering $\\beta$")
ax2.set_ylabel('sample size / dimension')
ax2.set_xlabel('sparsity / dimension')
for ax in [ax1, ax2]:
ax.margins(x=0, y=0)